Les fondamentaux des Large Language Models (LLM)

Les Large Language Models (LLM) comme GPT (Generative Pretrained Transformer) sont des technologies de pointe dans le domaine de l’intelligence artificielle. Ces modèles ont transformé la façon dont les machines comprennent et génèrent le langage naturel. Dans cet article, nous allons explorer les bases des LLM, leur fonctionnement, leurs applications, et les défis qu’ils posent.
Introduction aux LLM
Un Large Language Model (LLM) est un modèle d’apprentissage automatique qui traite et génère le langage naturel. Ces modèles sont formés sur d’énormes ensembles de données textuelles pour apprendre les subtilités de la langue.
Caractéristiques des LLM
- Taille : Les LLM sont caractérisés par le nombre massif de paramètres qu’ils contiennent, souvent allant en milliards ou même en trillions.
- Pré-entraînement : Ils sont pré-entraînés sur de vastes corpus de texte, ce qui leur permet d’apprendre une grande variété de motifs linguistiques et de connaissances générales.
- Fine-tuning : Les LLM peuvent être ensuite affinés sur des tâches spécifiques pour améliorer leurs performances dans des domaines particuliers.
Comment fonctionnent les LLM ?
Les LLM utilisent des architectures de réseau neuronal, telles que les Transformers, qui leur permettent de traiter le texte en tenant compte du contexte large de la conversation ou du document.
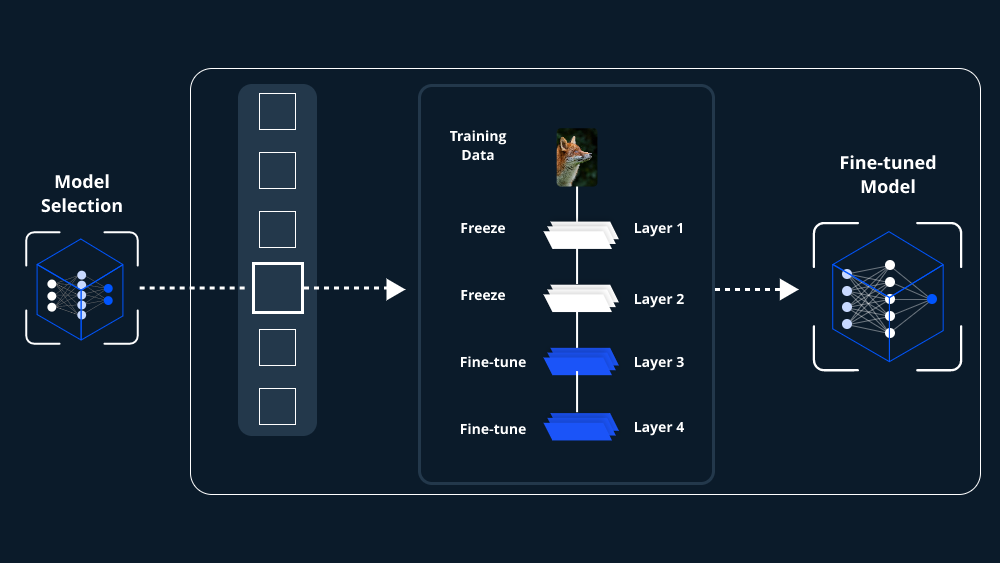
Processus d’entraînement
- Pré-entraînement : Le modèle est entraîné pour prédire le mot suivant dans une séquence de mots, en apprenant des patterns dans un large corpus textuel.
- Fine-tuning : Après le pré-entraînement, le modèle est ajusté pour des tâches spécifiques, améliorant sa précision pour ces applications.
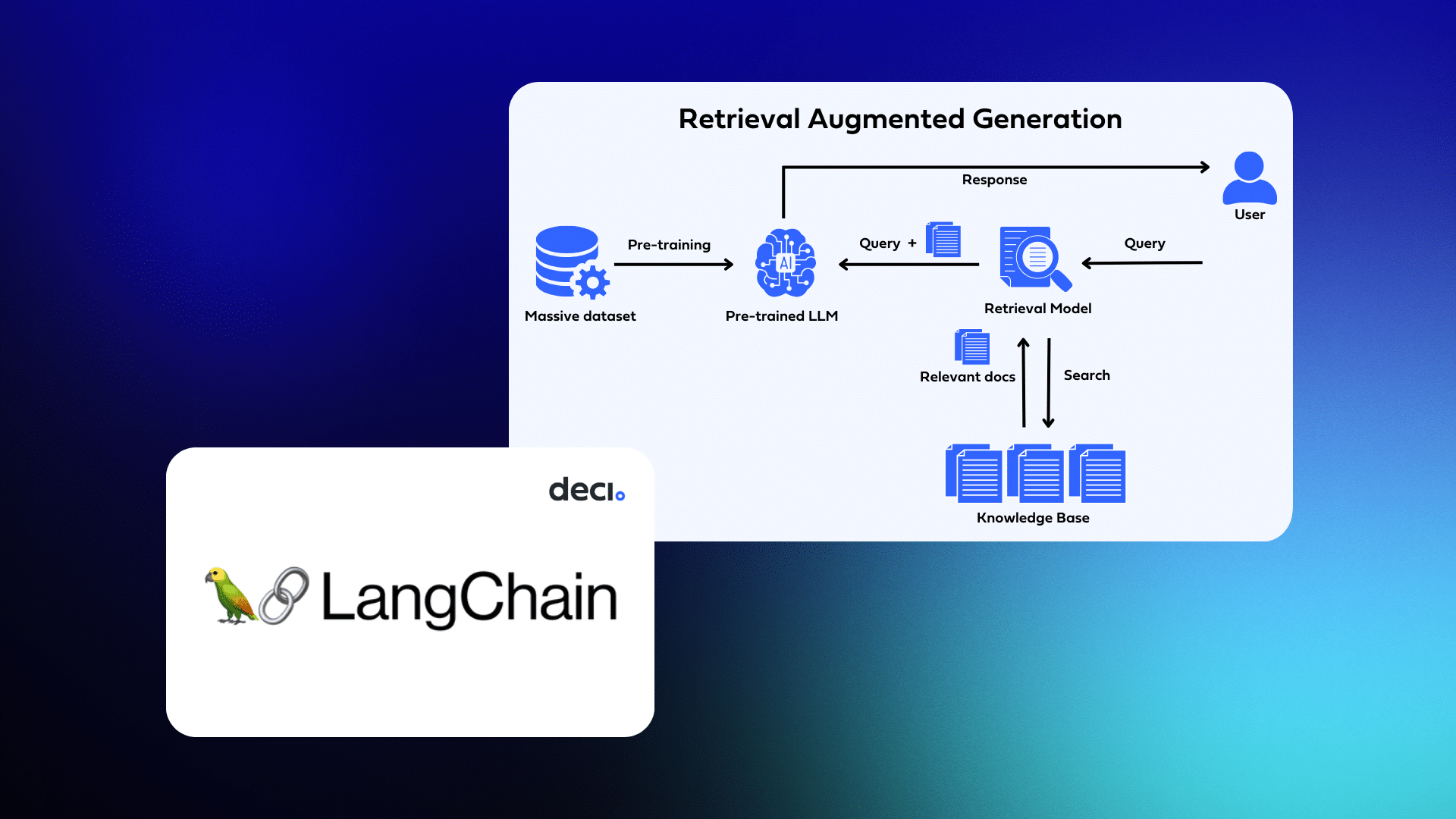
Introduction au Retrieval-Augmented Generation (RAG)
Le modèle Retrieval-Augmented Generation (RAG) est une avancée significative dans le domaine des LLM. RAG combine la puissance des modèles de langage pré-entraînés avec des techniques de récupération d’informations pour améliorer la qualité et la précision des réponses générées.
Fonctionnement du RAG
- Recherche d’informations : Avant de générer une réponse, RAG effectue une recherche dans une base de données ou un ensemble de documents pour trouver des informations pertinentes.
- Génération de réponse : En utilisant les informations récupérées, le modèle génère une réponse qui est non seulement basée sur son entraînement préalable mais aussi enrichie par des faits spécifiques extraits des documents de référence.
Avantages du RAG
- Précision accrue : En intégrant des informations spécifiques et vérifiables, RAG produit des réponses plus précises et informatives.
- Adaptabilité : Ce modèle peut être adapté à des tâches spécifiques où l’exactitude et la richesse des informations sont cruciales, comme dans les domaines médical, juridique ou scientifique.
- Réduction du biais : En s’appuyant sur des sources d’information variées et actualisées, RAG peut potentiellement réduire le biais inhérent à l’entraînement sur des ensembles de données historiques.
Ressources
- [Documentation ChatGPT](Using RAG for Enhancing Chatbot Responses
Applications pratiques des LLM
- Génération de contenu : Créer des articles, des scripts, et même du code.
- Assistance virtuelle : Pouvoir répondre à des questions et effectuer des tâches en langage naturel.
- Traduction automatique : Traduire des textes entre différentes langues avec une grande fluidité.
- Analyse de sentiment : Comprendre les émotions et les opinions exprimées dans le texte.
Le Potentiel Transformateur des LLM
Les Large Language Models (LLM) ont le potentiel de transformer radicalement divers secteurs en rendant les interactions entre l’homme et la machine plus naturelles et intuitives. Dans le domaine de l’éducation, par exemple, ils peuvent fournir un tutorat personnalisé à grande échelle, adapté au niveau et aux besoins spécifiques de chaque apprenant. Dans le secteur de la santé, ils ont le potentiel d’analyser des quantités massives de littérature médicale pour assister dans le diagnostic ou la recherche de nouveaux traitements.
Défis Techniques Spécifiques des LLM
Les LLM sont confrontés à des défis techniques majeurs. La gestion de la quantité massive de données nécessaires à leur entraînement nécessite d’importantes ressources informatiques. De plus, l’interprétation des résultats générés peut parfois produire des sorties inattendues ou incohérentes, nécessitant une surveillance humaine et des ajustements constants.

Comprendre le “Black Box”
La nature “boîte noire” de ces modèles représente un défi significatif. Bien qu’ils produisent des résultats impressionnants, comprendre comment ils arrivent à ces conclusions est souvent difficile, soulevant des questions de transparence et de fiabilité.
Implications Éthiques de l’Utilisation des LLM
Les implications éthiques de l’utilisation des LLM sont vastes et complexes. La question du biais dans les données d’entraînement est particulièrement préoccupante, car elle peut conduire à des résultats discriminatoires ou injustes.
Confidentialité et Sécurité
La confidentialité et la sécurité des données sont des préoccupations majeures avec les LLM. Ces modèles nécessitent d’accéder à de vastes ensembles de données, y compris des informations potentiellement sensibles, ce qui nécessite une protection rigoureuse contre les accès non autorisés ou les abus.
Authenticité et Propriété Intellectuelle
L’authenticité et la propriété intellectuelle sont au cœur des débats dans un monde où les LLM peuvent générer du contenu comparable à celui créé par des humains. Déterminer la paternité et protéger les droits d’auteur devient un défi majeur dans ce contexte.
Conclusion
Les LLM et les modèles tels que RAG représentent une avancée significative dans le domaine de l’intelligence artificielle, offrant des possibilités impressionnantes pour la génération et la compréhension du langage. Cependant, leur développement et leur utilisation doivent être attentivement gérés pour aborder les défis éthiques et techniques qu’ils posent.
Vous pouvez retrouver nos autres articles :